分组选择数据
主要介绍MySQL是如何实现分组数据的,以便能汇总表内容的子集。这涉及了两个SELECT子句,分别是GROUP BY 和 HAVING;分组可以将一个整表分为多个逻辑组,以便能对每个组进行聚集计算。
GROUP BY 与 聚合函数
任务描述
本关任务:使用GROUP BY关键字结合聚合函数将数据进行分组。
相关知识
在之前的实训中我们简单的提到过GROUP BY关键字,本实训让我们进一步了解GROUP BY与聚合函数的使用。
为了完成本关任务,你需要掌握:
GROUP BY与聚合函数的结合使用;GROUP BY中SELECT指定的字段限制。
GROUP BY与聚合函数的使用
基本格式:select [聚合函数] 字段名 from 表名 [where 查询条件] [group by 字段名]
先提供表Info结构如下:
| category | count | digest |
|---|---|---|
| a | 5 | a2002 |
| a | 2 | a2001 |
| a | 11 | a2001 |
| b | 10 | b2003 |
| b | 6 | b2002 |
| b | 3 | b2001 |
| c | 9 | c2005 |
| c | 9 | c2004 |
| c | 8 | c2003 |
| c | 7 | c2002 |
| c | 4 | c2001 |
示例:将表中数据分类并汇总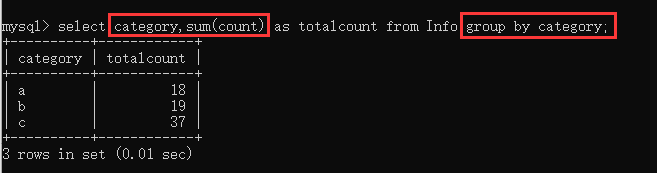
GROUP BY中SELECT指定的字段限制
示例:select category,sum(count),disgest from info group by category;
执行后会提示下错误,如下图。这就是需要注意的一点,在select指定的字段要么就要包含在Group By语句的后面,作为分组的依据;要么就要被包含在聚合函数中。
编程要求
在右侧编辑器补充代码,对年级Id和性别进行分组,分别统计表中2、3、4年级的男生总人数和女生总人数。
student表数据结构如下:
| stuId | gradeId | sex |
|---|---|---|
| 0201 | 2 | 男 |
| 0221 | 2 | 男 |
| 0319 | 3 | 女 |
| 0508 | 5 | 男 |
| 0610 | 6 | 女 |
| 0101 | 1 | 男 |
| 0224 | 2 | 女 |
| 0413 | 4 | 女 |
要求输出结果显示如下: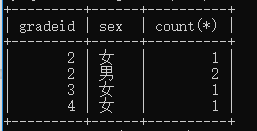
测试说明
平台会对你编写的代码进行测试:
预期输出:
1 | |
我的代码
1 | |
使用 HAVING 与 ORDER BY
任务描述
本关任务:按照要求编写sql查询语句。
相关知识
为了完成本关任务,你需要掌握:
- 使用
having子句进行分组筛选; Having与Where的区别;Group By和Order By。
使用having子句进行分组筛选
简单来说,having子句用来对分组后的数据进行筛选,即having针对查询结果中的列发挥筛选数据作用。因此having通常与Group by连用。
基本格式:select [聚合函数] 字段名 from 表名 [where 查询条件] [group by 字段名] [having 字段名 筛选条件]
表Info的数据信息仍如下:
| category | count | digest |
|---|---|---|
| a | 5 | a2002 |
| a | 2 | a2001 |
| a | 11 | a2001 |
| b | 20 | b2003 |
| b | 15 | b2002 |
| b | 3 | b2001 |
| c | 9 | c2005 |
| c | 9 | c2004 |
| c | 8 | c2003 |
| c | 7 | c2002 |
| c | 4 | c2001 |
示例:查询将表中数据分类后数量大于20的类别信息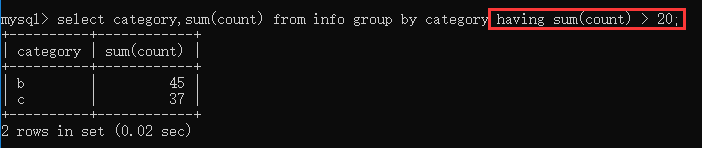
select语句中,where、group by、having子句和聚合函数的执行次序如下:
where子句从数据源中去除不符合条件的数据;- 然后
group by子句搜集数据行到各个组中; - 接着统计函数为各个组计算统计值;
- 最后
having子句去掉不符合其组搜索条件的各组数据行。
Having与Where的区别
where子句都可以用having代替,区别在于where过滤行,having过滤分组;
where子句的作用是在对查询结果进行分组前,将不符合where条件的行去掉,即在分组之前过滤数据,where条件中不能包含聚组函数,使用where条件过滤出特定的行;having子句的作用是筛选满足条件的组,即在分组之后过滤数据,条件中经常包含聚组函数,使用having条件过滤出特定的组,也可以使用多个分组标准进行分组。
having结合where示例: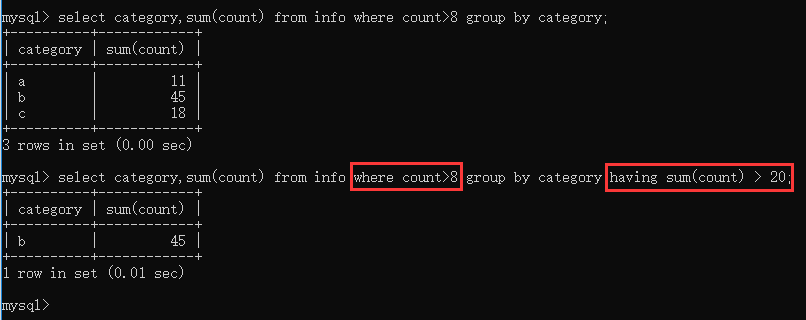
Group By 和 Order By
基本格式select [聚合函数] 字段名 from 表名 [where 查询条件] [group by 字段名] [order by 字段名 排序方向]
示例:(以降序方式输出数据分类的汇总)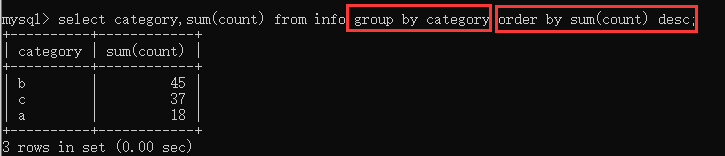
若分组字段和排序字段一样时,可不需要order by关键字,则只需告知排序方向,即可简写成: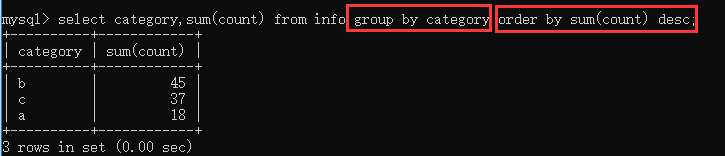
编程要求
根据提示,在右侧编辑器补充代码:
我们要评选三好学生,条件是至少有两门课程在90分以上(包括90分)才能有资格,请列出符合的学生的学号(
sno)及其90分以上(包括90分)科目总数;学校评选先进学生,要求平均成绩大于90分(包括90分)的学生都有资格,并且语文课必须在95分以上(包括95分),请列出有资格的学生的学号(
sno)及其科目的平均分。
给定数据表tb_grade格式如下:
| sno | pno | score |
|---|---|---|
| 1 | 语文 | 95 |
| 1 | 数学 | 98 |
| 1 | 英语 | 90 |
| 2 | 语文 | 89 |
| 2 | 数学 | 91 |
| 2 | 英语 | 92 |
| 3 | 语文 | 85 |
| 3 | 数学 | 88 |
| 3 | 英语 | 96 |
| 4 | 语文 | 95 |
| 4 | 数学 | 89 |
| 4 | 英语 | 88 |
测试说明
平台会对你编写的代码进行测试:
预期输出:
1 | |
我的代码
1 | |